🚀 Fase 5 – Uniones de Datasets en PySpark con funciones de spark.sql en Databricks ♾️
- 20 ago 2025
- 1 min de lectura
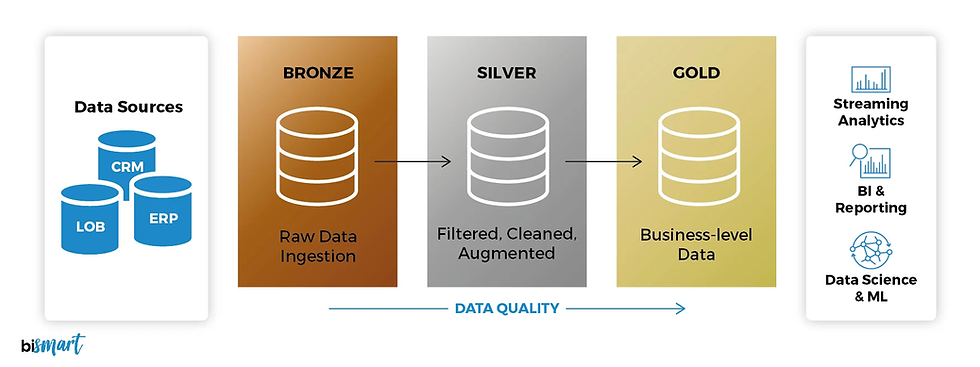
Cuando hablamos de manipulación de datos en el mundo real, es casi imposible no encontrarnos con la necesidad de unir información proveniente de diferentes fuentes. En PySpark, dentro de Databricks, la operación más común para lograr esto es el join, que nos permite combinar datasets de manera columnar, es decir, alineando datos en función de una o varias columnas clave.

En esta primera parte, me centro en las uniones columnar. Es decir, cuando queremos enriquecer un dataset con columnas adicionales provenientes de otra fuente. En PySpark se realiza con join, mientras que en otras librerías como Pandas o Polars, se utilizan funciones como merge o join.
📌 En la próxima publicación, exploraremos también las uniones verticales (tipo concat), y cómo aprovechar al máximo la potencia de Databricks para trabajar con grandes volúmenes de datos de manera eficiente. Crear una base sólida en este tipo de operaciones es clave si buscas crecer en el ámbito de Data Engineering y Data Science.



Comentarios